We've seen that the difficulty in dealing with concurrent processes is
rooted in the need to consider the interleaving of the order of events
in the different processes. For example, suppose we have two
processes, one with three ordered events (a,b,c) and one with three
ordered events (x,y,z). If the two processes run concurrently, with
no constraints on how their execution is interleaved, then there are
20 different possible orderings for the events that are consistent
with the individual orderings for the two processes:
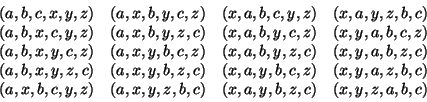
As programmers designing this system, we would have to consider the effects of each of these 20 orderings and check that each behavior is acceptable. Such an approach rapidly becomes unwieldy as the numbers of processes and events increase.
A more practical approach to the design of concurrent systems is to devise general mechanisms that allow us to constrain the interleaving of concurrent processes so that we can be sure that the program behavior is correct. Many mechanisms have been developed for this purpose. In this section, we describe one of them, the serializer.
Serializing access to shared state
Serialization implements the following idea: Processes will execute concurrently, but there will be certain collections of procedures that cannot be executed concurrently. More precisely, serialization creates distinguished sets of procedures such that only one execution of a procedure in each serialized set is permitted to happen at a time. If some procedure in the set is being executed, then a process that attempts to execute any procedure in the set will be forced to wait until the first execution has finished.
We can use serialization to control access to shared variables. For example, if we want to update a shared variable based on the previous value of that variable, we put the access to the previous value of the variable and the assignment of the new value to the variable in the same procedure. We then ensure that no other procedure that assigns to the variable can run concurrently with this procedure by serializing all of these procedures with the same serializer. This guarantees that the value of the variable cannot be changed between an access and the corresponding assignment.
Serializers in Scheme
To make the above mechanism more concrete, suppose that we have extended Scheme to include a procedure called parallel-execute:
(parallel-execute p1 p2 ... pk)Each p must be a procedure of no arguments. Parallel-execute creates a separate process for each p, which applies p (to no arguments). These processes all run concurrently.
![[*]](../image/foot_motif.gif)
As an example of how this is used, consider
(define x 10)This creates two concurrent processes--P1, which sets x to x times x, and P2, which increments x. After execution is complete, x will be left with one of five possible values, depending on the interleaving of the events of P1 and P2:(parallel-execute (lambda () (set! x (* x x))) (lambda () (set! x (+ x 1))))
| 101: | P1 sets x to 100 and then P2 increments x to 101. |
| 121: | P2 increments x to 11 and then P1 sets x to x times x. |
| 110: | P2 changes x from 10 to 11 between the two times that P1 accesses the value of x during the evaluation of (* x x). |
| 11: | P2 accesses x, then P1 sets x to 100, then P2 sets x. |
| 100: | P1 accesses x (twice), then P2 sets x to 11, then P1 sets x. |
We can constrain the concurrency by using serialized procedures, which are created by serializers. Serializers are constructed by makeserializer, whose implementation is given below. A serializer takes a procedure as argument and returns a serialized procedure that behaves like the original procedure. All calls to a given serializer return serialized procedures in the same set.
Thus, in contrast to the example above, executing
(define x 10)can produce only two possible values for x, 101 or 121. The other possibilities are eliminated, because the execution of P1 and P2 cannot be interleaved.(define s (make-serializer))
(parallel-execute (s (lambda () (set! x (* x x)))) (s (lambda () (set! x (+ x 1)))))
Here is a version of the make-account procedure from
section ![[*]](../image/cross_ref_motif.gif) , where the deposits and
withdrawals have been serialized:
, where the deposits and
withdrawals have been serialized:
(define (make-account balance)
(define (withdraw amount)
(if (>= balance amount)
(begin (set! balance (- balance amount))
balance)
"Insufficient funds"))
(define (deposit amount)
(set! balance (+ balance amount))
balance)
(let ((protected (make-serializer)))
(define (dispatch m)
(cond ((eq? m 'withdraw) (protected withdraw))
((eq? m 'deposit) (protected deposit))
((eq? m 'balance) balance)
(else (error "Unknown request - MAKE-ACCOUNT"
m))))
dispatch))
With this implementation, two processes cannot be withdrawing from or
depositing into a single account concurrently. This eliminates the source
of the error illustrated in figure , where Peter
changes the account balance between the times when Paul accesses the
balance to compute the new value and when Paul actually performs the
assignment. On the other hand, each account has its own serializer,
so that deposits and withdrawals for different accounts can proceed
concurrently.
Exercise. Which of the five possibilities in the parallel execution shown above remain if we instead serialize execution as follows:
(define x 10)(define s (make-serializer))
(parallel-execute (lambda () (set! x ((s (lambda () (* x x)))))) (s (lambda () (set! x (+ x 1)))))
Exercise. Give all possible values of x that can result from executing
(define x 10)Which of these possibilities remain if we instead use serialized procedures:(parallel-execute (lambda () (set! x (* x x))) (lambda () (set! x (* x x x))))
(define x 10)(define s (make-serializer))
(parallel-execute (s (lambda () (set! x (* x x)))) (s (lambda () (set! x (* x x x)))))
Exercise. Ben Bitdiddle worries that it would be better to implement the bank account as follows (where the commented line has been changed):
(define (make-account balance)
(define (withdraw amount)
(if (>= balance amount)
(begin (set! balance (- balance amount))
balance)
"Insufficient funds"))
(define (deposit amount)
(set! balance (+ balance amount))
balance)
;; continued on next page
(let ((protected (make-serializer)))
(define (dispatch m)
(cond ((eq? m 'withdraw) (protected withdraw))
((eq? m 'deposit) (protected deposit))
((eq? m 'balance)
((protected (lambda () balance)))) ; serialized
(else (error "Unknown request - MAKE-ACCOUNT"
m))))
dispatch))
because allowing unserialized access to the bank balance can result in
anomalous behavior. Do you agree? Is there any scenario that
demonstrates Ben's concern?
Exercise. Ben Bitdiddle suggests that it's a waste of time to create a new serialized procedure in response to every withdraw and deposit message. He says that make-account could be changed so that the calls to protected are done outside the dispatch procedure. That is, an account would return the same serialized procedure (which was created at the same time as the account) each time it is asked for a withdrawal procedure.
(define (make-account balance)
(define (withdraw amount)
(if (>= balance amount)
(begin (set! balance (- balance amount))
balance)
"Insufficient funds"))
(define (deposit amount)
(set! balance (+ balance amount))
balance)
(let ((protected (make-serializer)))
(let ((protected-withdraw (protected withdraw))
(protected-deposit (protected deposit)))
(define (dispatch m)
(cond ((eq? m 'withdraw) protected-withdraw)
((eq? m 'deposit) protected-deposit)
((eq? m 'balance) balance)
(else (error "Unknown request - MAKE-ACCOUNT"
m))))
dispatch)))
Is this a safe change to make? In particular, is there any difference in
what concurrency is allowed by these two versions of make-accountComplexity of using multiple shared resources
Serializers provide a powerful abstraction that helps isolate the complexities of concurrent programs so that they can be dealt with carefully and (hopefully) correctly. However, while using serializers is relatively straightforward when there is only a single shared resource (such as a single bank account), concurrent programming can be treacherously difficult when there are multiple shared resources.
To illustrate one of the difficulties that can arise, suppose we wish to swap
the balances in two bank accounts. We access each account to find the
balance, compute the difference between the balances, withdraw this
difference from one account, and deposit it in the other account. We
could implement this as follows:
(define (exchange account1 account2)
(let ((difference (- (account1 'balance)
(account2 'balance))))
((account1 'withdraw) difference)
((account2 'deposit) difference)))
This procedure works well when only a single process is trying to do
the exchange. Suppose, however, that Peter and Paul both have access
to accounts a1, a2, and a3, and that
Peter exchanges a1 and
a2 while Paul concurrently exchanges a1 and a3.
Even with account deposits and withdrawals
serialized for individual accounts (as in the make-account
procedure shown above in this section), exchange can still
produce incorrect results. For example, Peter might compute the
difference in the balances for a1 and a2, but then Paul
might change the balance in a1 before Peter is able to complete
the exchange.
For correct behavior, we must arrange for the exchange procedure
to lock out any other concurrent accesses to the accounts during the
entire time of the exchange.
One way we can accomplish this is by using both accounts' serializers
to serialize the entire exchange procedure.
To do this, we will arrange for access to an account's serializer.
Note that we are deliberately
breaking the modularity of the bank-account object by exposing the
serializer. The following version of make-account is identical
to the original version given in
section , except that a serializer is
provided to protect the balance variable, and the serializer is
exported via message passing:
(define (make-account-and-serializer balance)
(define (withdraw amount)
(if (>= balance amount)
(begin (set! balance (- balance amount))
balance)
"Insufficient funds"))
(define (deposit amount)
(set! balance (+ balance amount))
balance)
(let ((balance-serializer (make-serializer)))
(define (dispatch m)
(cond ((eq? m 'withdraw) withdraw)
((eq? m 'deposit) deposit)
((eq? m 'balance) balance)
((eq? m 'serializer) balance-serializer)
(else (error "Unknown request - MAKE-ACCOUNT"
m))))
dispatch))
We can use this to do serialized deposits and withdrawals. However,
unlike our earlier serialized account, it is now the responsibility of
each user of bank-account objects to explicitly manage the
serialization, for example as follows:
(define (deposit account amount)
(let ((s (account 'serializer))
(d (account 'deposit)))
((s d) amount)))
Exporting the serializer in this way gives us enough flexibility to implement a serialized exchange program. We simply serialize the original exchange procedure with the serializers for both accounts:
(define (serialized-exchange account1 account2)
(let ((serializer1 (account1 'serializer))
(serializer2 (account2 'serializer)))
((serializer1 (serializer2 exchange))
account1
account2)))
Exercise.
Suppose that the balances in three accounts start out as $10, $20,
and $30, and that multiple processes run, exchanging the balances in
the accounts. Argue that if the processes are run sequentially,
after any number of concurrent exchanges, the account balances should be
$10, $20, and $30 in some order.
Draw a timing diagram like the one in figure to
show how this condition can be violated if the exchanges are
implemented using the first version of the account-exchange program in
this section. On the other hand, argue that even with this
exchange program, the sum of the balances in the accounts will be
preserved. Draw a timing diagram to show how even this condition would
be violated if we did not serialize the transactions
on individual accounts.
Exercise. Consider the problem of transferring an amount from one account to another. Ben Bitdiddle claims that this can be accomplished with the following procedure, even if there are multiple people concurrently transferring money among multiple accounts, using any account mechanism that serializes deposit and withdrawal transactions, for example, the version of make-account in the text above.
(define (transfer from-account to-account amount) ((from-account 'withdraw) amount) ((to-account 'deposit) amount))Louis Reasoner claims that there is a problem here, and that we need to use a more sophisticated method, such as the one required for dealing with the exchange problem. Is Louis right? If not, what is the essential difference between the transfer problem and the exchange problem? (You should assume that the balance in from-account is at least amount.)
Exercise. Louis Reasoner thinks our bank-account system is unnecessarily complex and error-prone now that deposits and withdrawals aren't automatically serialized. He suggests that make-account-and-serializer should have exported the serializer (for use by such procedures as serialized-exchange) in addition to (rather than instead of) using it to serialize accounts and deposits as makeaccount did. He proposes to redefine accounts as follows:
(define (make-account-and-serializer balance)
(define (withdraw amount)
(if (>= balance amount)
(begin (set! balance (- balance amount))
balance)
"Insufficient funds"))
(define (deposit amount)
(set! balance (+ balance amount))
balance)
(let ((balance-serializer (make-serializer)))
(define (dispatch m)
(cond ((eq? m 'withdraw) (balance-serializer withdraw))
((eq? m 'deposit) (balance-serializer deposit))
((eq? m 'balance) balance)
((eq? m 'serializer) balance-serializer)
(else (error "Unknown request - MAKE-ACCOUNT"
m))))
dispatch))
Then deposits are handled as with the original make-account:
(define (deposit account amount) ((account 'deposit) amount))Explain what is wrong with Louis's reasoning. In particular, consider what happens when serialized-exchange is called.
Implementing serializers
We implement serializers in terms of a more primitive synchronization
mechanism called a
mutex. A mutex is an object that supports
two operations--the mutex can be
acquired, and the mutex can be
released. Once a mutex has been acquired, no other acquire
operations on that mutex may proceed until the mutex is released.
In our implementation, each
serializer has an associated mutex. Given a procedure p, the
serializer returns a procedure that acquires the mutex, runs p,
and then releases the mutex. This ensures that only one of the
procedures produced by the serializer can be running at once, which is
precisely the serialization property that we need to guarantee.
(define (make-serializer)
(let ((mutex (make-mutex)))
(lambda (p)
(define (serialized-p . args)
(mutex 'acquire)
(let ((val (apply p args)))
(mutex 'release)
val))
serialized-p)))
The mutex is a mutable object (here we'll use a one-element list, which we'll refer to as a cell) that can hold the value true or false. When the value is false, the mutex is available to be acquired. When the value is true, the mutex is unavailable, and any process that attempts to acquire the mutex must wait.
Our mutex constructor make-mutex begins by initializing the cell
contents to false. To acquire the mutex, we test the cell. If the
mutex is available, we set the cell contents to true and proceed.
Otherwise, we wait in a loop, attempting to acquire over and over
again, until we find that the mutex is available. To release the
mutex, we set the cell contents to false.
(define (make-mutex)
(let ((cell (list false)))
(define (the-mutex m)
(cond ((eq? m 'acquire)
(if (test-and-set! cell)
(the-mutex 'acquire))) ; retry
((eq? m 'release) (clear! cell))))
the-mutex))
(define (clear! cell)
(set-car! cell false))
Test-and-set! tests the cell and returns the result of the test. In addition, if the test was false, test-and-set! sets the cell contents to true before returning false. We can express this behavior as the following procedure:
(define (test-and-set! cell)
(if (car cell)
true
(begin (set-car! cell true)
false)))
However, this implementation of test-and-set! does not suffice
as it stands. There is a crucial subtlety here, which is the
essential place where concurrency control enters the system: The
test-and-set! operation must be performed
atomically. That
is, we must guarantee that, once a process has tested the cell and
found it to be false, the cell contents will actually be set to true
before any other process can test the cell. If we do not make this
guarantee, then the mutex can fail in a way similar to the
bank-account failure in figure . (See
exercise .)
The actual implementation of test-and-set! depends on the
details of how our system runs concurrent processes. For example, we
might be executing concurrent processes on a sequential processor
using a
time-slicing mechanism that cycles through the processes,
permitting each process to run for a short time before interrupting it
and moving on to the next process. In that case, test-and-set!
can work by disabling time slicing during the testing and setting.
Alternatively, multiprocessing computers provide instructions that
support atomic operations directly in hardware.
Exercise.
Suppose that we implement test-and-set! using an ordinary
procedure as shown in the text, without attempting to make the operation
atomic. Draw a timing diagram like the one in
figure to demonstrate how the mutex
implementation can fail by allowing two processes to acquire the mutex
at the same time.
Exercise. A semaphore (of size n) is a generalization of a mutex. Like a mutex, a semaphore supports acquire and release operations, but it is more general in that up to n processes can acquire it concurrently. Additional processes that attempt to acquire the semaphore must wait for release operations. Give implementations of semaphores
a. in terms of mutexes
b. in terms of atomic test-and-set! operations.
Deadlock
Now that we have seen how to implement serializers, we can see that account exchanging still has a problem, even with the serializedexchange procedure above. Imagine that Peter attempts to exchange a1 with a2 while Paul concurrently attempts to exchange a2 with a1. Suppose that Peter's process reaches the point where it has entered a serialized procedure protecting a1 and, just after that, Paul's process enters a serialized procedure protecting a2. Now Peter cannot proceed (to enter a serialized procedure protecting a2) until Paul exits the serialized procedure protecting a2. Similarly, Paul cannot proceed until Peter exits the serialized procedure protecting a1. Each process is stalled forever, waiting for the other. This situation is called a deadlock. Deadlock is always a danger in systems that provide concurrent access to multiple shared resources.
One way to avoid the deadlock in this situation is to give each
account a unique identification number and rewrite serialized-exchange so
that a process will always attempt to enter a procedure protecting the
lowest-numbered account first. Although this method works well for
the exchange problem, there are other situations that require more
sophisticated deadlock-avoidance techniques, or where deadlock cannot
be avoided at all. (See exercises
and .)
Exercise. Explain in detail why the deadlock-avoidance method described above, (i.e., the accounts are numbered, and each process attempts to acquire the smaller-numbered account first) avoids deadlock in the exchange problem. Rewrite serialized-exchange to incorporate this idea. (You will also need to modify make-account so that each account is created with a number, which can be accessed by sending an appropriate message.)
Exercise. Give a scenario where the deadlock-avoidance mechanism described above does not work. (Hint: In the exchange problem, each process knows in advance which accounts it will need to get access to. Consider a situation where a process must get access to some shared resources before it can know which additional shared resources it will require.)
Concurrency, time, and communication
We've seen how programming concurrent systems requires controlling the ordering of events when different processes access shared state, and we've seen how to achieve this control through judicious use of serializers. But the problems of concurrency lie deeper than this, because, from a fundamental point of view, it's not always clear what is meant by ``shared state.''
Mechanisms such as test-and-set! require processes to examine a
global shared flag at arbitrary times. This is problematic and
inefficient to implement in modern high-speed processors, where
due to optimization techniques such as pipelining and cached memory,
the contents of memory
may not be in a consistent state at every instant. In contemporary
multiprocessing systems, therefore, the serializer paradigm is being
supplanted by new approaches to concurrency control.
The problematic aspects of shared state also arise
in large, distributed systems. For
instance, imagine a
distributed banking system where individual branch banks maintain
local values for bank balances and periodically compare these with
values maintained by other branches. In such a system the value of
``the account balance'' would be undetermined, except right after
synchronization.
If Peter deposits money in an account he holds
jointly with Paul, when should we say that the account balance has
changed--when the balance in the local branch changes, or not until
after the synchronization?
And if Paul accesses the account from a
different branch, what are the reasonable constraints to place on the
banking system such that the behavior is ``correct''?
The only thing that might matter for
correctness is the behavior observed by Peter and Paul individually
and the ``state'' of the account immediately after synchronization.
Questions about the
``real'' account balance or the order of events between synchronizations
may be irrelevant or meaningless.
The basic phenomenon here is that synchronizing different processes,
establishing shared state, or imposing an order on events requires
communication among the processes. In essence, any notion of time in
concurrency control must be intimately tied to communication. It is
intriguing that a similar connection between time and communication
also arises in the
Theory of Relativity, where the speed of light (the
fastest signal that can be used to synchronize events) is a
fundamental constant relating time and space. The
complexities we encounter in dealing with time and state in our
computational models may in fact mirror a fundamental complexity of
the physical universe.