In working with compound data, we've stressed how data abstraction permits us to design programs without becoming enmeshed in the details of data representations, and how abstraction preserves for us the flexibility to experiment with alternative representations. In this section, we introduce another powerful design principle for working with data structures--the use of conventional interfaces.
In section ![[*]](../image/cross_ref_motif.gif) we saw how program
abstractions, implemented as higher-order procedures, can capture
common patterns in programs that deal with numerical data. Our
ability to formulate analogous operations for working with compound
data depends crucially on the style in which we manipulate our data
structures. Consider, for example, the following procedure, analogous
to the count-leaves procedure of section , which
takes a tree as argument and computes the sum of the squares of the
leaves that are odd:
we saw how program
abstractions, implemented as higher-order procedures, can capture
common patterns in programs that deal with numerical data. Our
ability to formulate analogous operations for working with compound
data depends crucially on the style in which we manipulate our data
structures. Consider, for example, the following procedure, analogous
to the count-leaves procedure of section , which
takes a tree as argument and computes the sum of the squares of the
leaves that are odd:
(define (sum-odd-squares tree)
(cond ((null? tree) 0)
((not (pair? tree))
(if (odd? tree) (square tree) 0))
(else (+ (sum-odd-squares (car tree))
(sum-odd-squares (cdr tree))))))
On the surface, this procedure is very different from the following
one, which constructs a list of all the even Fibonacci numbers
![]() ,
where k is less than or equal to a given integer n:
,
where k is less than or equal to a given integer n:
(define (even-fibs n)
(define (next k)
(if (> k n)
nil
(let ((f (fib k)))
(if (even? f)
(cons f (next (+ k 1)))
(next (+ k 1))))))
(next 0))
Despite the fact that these two procedures are structurally very different, a more abstract description of the two computations reveals a great deal of similarity. The first program
- enumerates the leaves of a tree;
- filters them, selecting the odd ones;
- squares each of the selected ones; and
- accumulates the results using +, starting with 0.
- enumerates the integers from 0 to n;
- computes the Fibonacci number for each integer;
- filters them, selecting the even ones; and
- accumulates the results using cons, starting with the empty list.
A signal-processing engineer would find it natural to conceptualize
these processes in terms of signals flowing through a cascade of
stages, each of which implements part of the program plan, as shown in
figure . In sum-odd-squares, we
begin with an
enumerator, which generates a ``signal''
consisting of the leaves of a given tree. This signal is passed
through a
filter, which eliminates all but the odd elements.
The resulting signal is in turn passed through a
map, which is a
``transducer'' that applies the square procedure to each
element. The output of the map is then fed to an
accumulator,
which combines the elements using +, starting from an initial 0.
The plan for even-fibs is analogous.
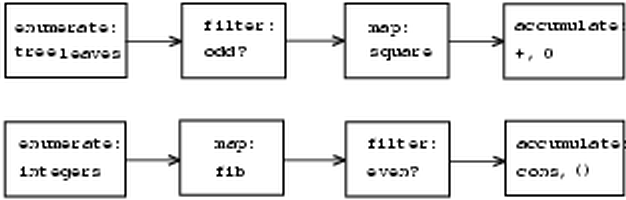
Unfortunately, the two procedure definitions above fail to exhibit this signal-flow structure. For instance, if we examine the sum-odd-squares procedure, we find that the enumeration is implemented partly by the null? and pair? tests and partly by the tree-recursive structure of the procedure. Similarly, the accumulation is found partly in the tests and partly in the addition used in the recursion. In general, there are no distinct parts of either procedure that correspond to the elements in the signal-flow description. Our two procedures decompose the computations in a different way, spreading the enumeration over the program and mingling it with the map, the filter, and the accumulation. If we could organize our programs to make the signal-flow structure manifest in the procedures we write, this would increase the conceptual clarity of the resulting code.
The key to organizing programs so as to more clearly reflect the
signal-flow structure is to concentrate on the ``signals'' that flow
from one stage in the process to the next. If we represent these
signals as lists, then we can use list operations to implement the
processing at each of the stages. For instance, we can implement the
mapping stages of the signal-flow diagrams using the map
procedure from section :
(map square (list 1 2 3 4 5)) (1 4 9 16 25)
Filtering a sequence to select only those elements that satisfy a given predicate is accomplished by
(define (filter predicate sequence)
(cond ((null? sequence) nil)
((predicate (car sequence))
(cons (car sequence)
(filter predicate (cdr sequence))))
(else (filter predicate (cdr sequence)))))
For example,
(filter odd? (list 1 2 3 4 5)) (1 3 5)
Accumulations can be implemented by
(define (accumulate op initial sequence)
(if (null? sequence)
initial
(op (car sequence)
(accumulate op initial (cdr sequence)))))
(accumulate + 0 (list 1 2 3 4 5))
15
(accumulate * 1 (list 1 2 3 4 5))
120
(accumulate cons nil (list 1 2 3 4 5))
(1 2 3 4 5)
All that remains to implement signal-flow diagrams is to enumerate the sequence of elements to be processed. For even-fibs, we need to generate the sequence of integers in a given range, which we can do as follows:
(define (enumerate-interval low high)
(if (> low high)
nil
(cons low (enumerate-interval (+ low 1) high))))
(enumerate-interval 2 7)
(2 3 4 5 6 7)
To enumerate the leaves of a tree, we can use
![[*]](../image/foot_motif.gif)
(define (enumerate-tree tree)
(cond ((null? tree) nil)
((not (pair? tree)) (list tree))
(else (append (enumerate-tree (car tree))
(enumerate-tree (cdr tree))))))
(enumerate-tree (list 1 (list 2 (list 3 4)) 5))
(1 2 3 4 5)
Now we can reformulate sum-odd-squares and even-fibs as in the signal-flow diagrams. For sum-odd-squares, we enumerate the sequence of leaves of the tree, filter this to keep only the odd numbers in the sequence, square each element, and sum the results:
(define (sum-odd-squares tree)
(accumulate +
0
(map square
(filter odd?
(enumerate-tree tree)))))
For even-fibs, we enumerate the integers from 0 to n, generate
the Fibonacci number for each of these integers, filter the resulting
sequence to keep only the even elements, and accumulate the results
into a list:
(define (even-fibs n)
(accumulate cons
nil
(filter even?
(map fib
(enumerate-interval 0 n)))))
The value of expressing programs as sequence operations is that this helps us make program designs that are modular, that is, designs that are constructed by combining relatively independent pieces. We can encourage modular design by providing a library of standard components together with a conventional interface for connecting the components in flexible ways.
Modular construction is a powerful strategy for controlling complexity in engineering design. In real signal-processing applications, for example, designers regularly build systems by cascading elements selected from standardized families of filters and transducers. Similarly, sequence operations provide a library of standard program elements that we can mix and match. For instance, we can reuse pieces from the sum-odd-squares and even-fibs procedures in a program that constructs a list of the squares of the first n+1 Fibonacci numbers:
(define (list-fib-squares n)
(accumulate cons
nil
(map square
(map fib
(enumerate-interval 0 n)))))
(list-fib-squares 10)
(0 1 1 4 9 25 64 169 441 1156 3025)
We can rearrange the pieces and use them in computing the product of
the odd integers in a sequence:
(define (product-of-squares-of-odd-elements sequence)
(accumulate *
1
(map square
(filter odd? sequence))))
(product-of-squares-of-odd-elements (list 1 2 3 4 5))
225
We can also formulate conventional data-processing applications in terms of sequence operations. Suppose we have a sequence of personnel records and we want to find the salary of the highest-paid programmer. Assume that we have a selector salary that returns the salary of a record, and a predicate programmer? that tests if a record is for a programmer. Then we can write
(define (salary-of-highest-paid-programmer records)
(accumulate max
0
(map salary
(filter programmer? records))))
These examples give just a hint of the vast range of operations that
can be expressed as sequence operations.
Sequences, implemented here as lists, serve
as a conventional interface that permits us to combine processing
modules. Additionally, when we uniformly represent structures as
sequences, we have localized the data-structure dependencies in our
programs to a small number of sequence operations. By changing these,
we can experiment with alternative representations of sequences, while
leaving the overall design of our programs intact. We will exploit
this capability in section , when we generalize the
sequence-processing paradigm to admit infinite sequences.
Exercise. Fill in the missing expressions to complete the following definitions of some basic list-manipulation operations as accumulations:
(define (map p sequence) (accumulate (lambda (x y) ??) nil sequence)) (define (append seq1 seq2) (accumulate cons ?? ??)) (define (length sequence) (accumulate ?? 0 sequence))
Exercise. Evaluating a polynomial in x at a given value of x can be
formulated as an accumulation. We evaluate the polynomial
using a well-known algorithm called Horner's rule, which structures the computation as
In other words, we start with an, multiply by x, add an-1, multiply by x, and so on, until we reach a0.
Fill in the following template to produce a procedure that evaluates a
polynomial using Horner's rule.
Assume that the coefficients of the
polynomial are arranged in a sequence, from a0 through an.
(define (horner-eval x coefficient-sequence)
(accumulate (lambda (this-coeff higher-terms) ??)
0
coefficient-sequence))
For example, to compute
1+3x+5x3+x5 at x=2 you would evaluate
(horner-eval 2 (list 1 3 0 5 0 1))
Exercise. Redefine count-leaves from section as an
accumulation:
(define (count-leaves t) (accumulate ?? ?? (map ?? ??)))
Exercise. The procedure accumulate-n is similar to accumulate except that it takes as its third argument a sequence of sequences, which are all assumed to have the same number of elements. It applies the designated accumulation procedure to combine all the first elements of the sequences, all the second elements of the sequences, and so on, and returns a sequence of the results. For instance, if s is a sequence containing four sequences, ((1 2 3) (4 5 6) (7 8 9) (10 11 12)), then the value of (accumulate-n + 0 s) should be the sequence (22 26 30). Fill in the missing expressions in the following definition of accumulate-n:
(define (accumulate-n op init seqs)
(if (null? (car seqs))
nil
(cons (accumulate op init ??)
(accumulate-n op init ??))))
Exercise. Suppose we represent vectors v=(vi) as sequences of numbers, and
matrices
m=(mij) as sequences of vectors (the rows of the matrix).
For example, the matrix
![\begin{displaymath}\left[
\begin{array}{llll}
1 & 2 & 3 & 4\\
4 & 5 & 6 & 6\\
6 & 7 & 8 & 9\\
\end{array}\right] \end{displaymath}](../image/img140.gif)
is represented as the sequence ((1 2 3 4) (4 5 6 6) (6 7 8 9)). With this representation, we can use sequence operations to concisely express the basic matrix and vector operations. These operations (which are described in any book on matrix algebra) are the following:
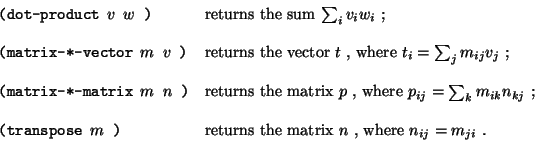
We can define the dot product as
(define (dot-product v w) (accumulate + 0 (map * v w)))Fill in the missing expressions in the following procedures for computing the other matrix operations. (The procedure accumulate-n is defined in exercise
.)
(define (matrix-*-vector m v)
(map ?? m))
(define (transpose mat)
(accumulate-n ?? ?? mat))
(define (matrix-*-matrix m n)
(let ((cols (transpose n)))
(map ?? m)))
Exercise. The accumulate procedure is also known as fold-right, because it combines the first element of the sequence with the result of combining all the elements to the right. There is also a fold-left, which is similar to fold-right, except that it combines elements working in the opposite direction:
(define (fold-left op initial sequence)
(define (iter result rest)
(if (null? rest)
result
(iter (op result (car rest))
(cdr rest))))
(iter initial sequence))
What are the values of
(fold-right / 1 (list 1 2 3)) (fold-left / 1 (list 1 2 3)) (fold-right list nil (list 1 2 3)) (fold-left list nil (list 1 2 3))Give a property that op should satisfy to guarantee that fold-right and foldleft will produce the same values for any sequence.
Exercise.
Complete the following definitions of reverse
(exercise ) in terms of foldright and
fold-left from exercise :
(define (reverse sequence) (fold-right (lambda (x y) ??) nil sequence)) (define (reverse sequence) (fold-left (lambda (x y) ??) nil sequence))
We can extend the sequence paradigm to include many
computations that are commonly expressed using nested loops.
Consider
this problem: Given a positive integer n, find all ordered pairs of
distinct positive integers i and j, where
![]() ,
such
that i +j is prime. For example, if n is 6, then the pairs are
the following:
,
such
that i +j is prime. For example, if n is 6, then the pairs are
the following:
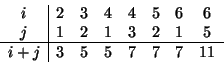
A natural way to organize this computation is to generate the sequence of all ordered pairs of positive integers less than or equal to n, filter to select those pairs whose sum is prime, and then, for each pair (i, j) that passes through the filter, produce the triple (i,j,i+j).
Here is a way to generate the sequence of pairs: For each integer
![]() ,
enumerate the integers j<i, and for each such i and j
generate the pair (i,j). In terms of sequence operations, we map
along the sequence (enumerate-interval 1 n). For each i in
this sequence, we map along the sequence (enumerate-interval 1 (-
i 1)). For each j in this latter sequence, we generate the pair
(list i j). This gives us a sequence of pairs for each i.
Combining all the sequences for all the i (by accumulating with
append) produces the required sequence of pairs:
,
enumerate the integers j<i, and for each such i and j
generate the pair (i,j). In terms of sequence operations, we map
along the sequence (enumerate-interval 1 n). For each i in
this sequence, we map along the sequence (enumerate-interval 1 (-
i 1)). For each j in this latter sequence, we generate the pair
(list i j). This gives us a sequence of pairs for each i.
Combining all the sequences for all the i (by accumulating with
append) produces the required sequence of pairs:
(accumulate append
nil
(map (lambda (i)
(map (lambda (j) (list i j))
(enumerate-interval 1 (- i 1))))
(enumerate-interval 1 n)))
The combination of mapping and accumulating with append is so common in this
sort of program that we will isolate it as a separate procedure:
(define (flatmap proc seq) (accumulate append nil (map proc seq)))Now filter this sequence of pairs to find those whose sum is prime. The filter predicate is called for each element of the sequence; its argument is a pair and it must extract the integers from the pair. Thus, the predicate to apply to each element in the sequence is
(define (prime-sum? pair) (prime? (+ (car pair) (cadr pair))))Finally, generate the sequence of results by mapping over the filtered pairs using the following procedure, which constructs a triple consisting of the two elements of the pair along with their sum:
(define (make-pair-sum pair) (list (car pair) (cadr pair) (+ (car pair) (cadr pair))))Combining all these steps yields the complete procedure:
(define (prime-sum-pairs n)
(map make-pair-sum
(filter prime-sum?
(flatmap
(lambda (i)
(map (lambda (j) (list i j))
(enumerate-interval 1 (- i 1))))
(enumerate-interval 1 n)))))
Nested mappings are also useful for sequences other than those that
enumerate intervals. Suppose we wish to generate all the
permutations
of a set S; that is, all the ways of ordering the items in
the set. For instance, the permutations of ![]() are
are
![]() ,
,
![]() ,
,
![]() ,
,
![]() ,
,
![]() ,
and
,
and
![]() .
Here is a plan for generating the permutations of S:
For each item x in S, recursively generate the sequence of
permutations of S-x, and adjoin
x to the front of each one. This yields, for each x in S, the sequence
of permutations of S that begin with x. Combining these
sequences for all x gives all the permutations of S:
.
Here is a plan for generating the permutations of S:
For each item x in S, recursively generate the sequence of
permutations of S-x, and adjoin
x to the front of each one. This yields, for each x in S, the sequence
of permutations of S that begin with x. Combining these
sequences for all x gives all the permutations of S:
(define (permutations s)
(if (null? s) ; empty set?
(list nil) ; sequence containing empty set
(flatmap (lambda (x)
(map (lambda (p) (cons x p))
(permutations (remove x s))))
s)))
Notice how this strategy reduces the problem of generating
permutations of S to the problem of generating the permutations of
sets with fewer elements than S. In the terminal case, we work our
way down to the empty list, which represents a set of no elements.
For this, we generate (list nil), which is a sequence with one
item, namely the set with no elements. The remove procedure
used in permutations returns all the items in a given sequence
except for a given item. This can be expressed as a simple filter:
(define (remove item sequence)
(filter (lambda (x) (not (= x item)))
sequence))
Exercise.
Define a procedure
unique-pairs that, given an integer n,
generates the sequence of pairs (i,j) with
![]() .
Use
unique-pairs to simplify the definition of prime-sum-pairs
given above.
.
Use
unique-pairs to simplify the definition of prime-sum-pairs
given above.
Exercise. Write a procedure to find all ordered triples of distinct positive integers i, j, and k less than or equal to a given integer n that sum to a given integer s.
Exercise.
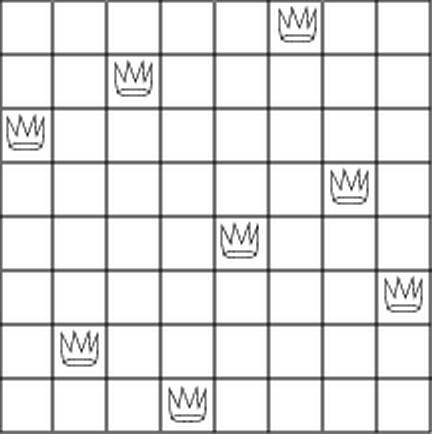
The ``eight-queens puzzle'' asks how to place eight queens on a chessboard so that no queen is in check from any other (i.e., no two queens are in the same row, column, or diagonal). One possible solution is shown in figure
. One way to solve the
puzzle is to work across the board, placing a queen in each column.
Once we have placed k-1 queens, we must place the kth queen in a
position where it does not check any of the queens already on the
board. We can formulate this approach recursively: Assume that we
have already generated the sequence of all possible ways to place
k-1 queens in the first k-1 columns of the board. For each of
these ways, generate an extended set of positions by placing a queen
in each row of the kth column. Now filter these, keeping only
the positions for which the queen in the kth column is safe with
respect to the other queens. This produces the sequence of all ways
to place k queens in the first k columns. By continuing this
process, we will produce not only one solution, but all solutions to
the puzzle.
We implement this solution as a procedure queens, which returns
a sequence of all solutions to the problem of placing n queens on an
![]() chessboard. Queens has an internal procedure
queen-cols that returns the sequence of all ways to place queens in
the first k columns of the board.
chessboard. Queens has an internal procedure
queen-cols that returns the sequence of all ways to place queens in
the first k columns of the board.
(define (queens board-size)
(define (queen-cols k)
(if (= k 0)
(list empty-board)
(filter
(lambda (positions) (safe? k positions))
(flatmap
(lambda (rest-of-queens)
(map (lambda (new-row)
(adjoin-position new-row k rest-of-queens))
(enumerate-interval 1 board-size)))
(queen-cols (- k 1))))))
(queen-cols board-size))
In this procedure rest-of-queens is a way to place k-1 queens
in the first k-1 columns, and new-row is a proposed row in
which to place the queen for the kth column. Complete the program
by implementing the representation for sets of board positions,
including the procedure adjoin-position, which adjoins a new row-column
position to a set of positions, and empty-board, which
represents an empty set of positions. You must also write the
procedure safe?, which determines for a set of positions,
whether the queen in the kth column is safe with respect to the
others. (Note that we need only check whether the new queen is
safe--the other queens are already guaranteed safe with respect to
each other.)
Exercise.
Louis Reasoner is having a terrible time doing exercise . His
queens procedure seems to work, but it runs extremely slowly.
(Louis never does manage to wait long enough for it to solve even the
![]() case.) When Louis asks Eva Lu Ator for help, she points
out that he has interchanged the order of the nested mappings in the
flatmap, writing it as
case.) When Louis asks Eva Lu Ator for help, she points
out that he has interchanged the order of the nested mappings in the
flatmap, writing it as
(flatmap
(lambda (new-row)
(map (lambda (rest-of-queens)
(adjoin-position new-row k rest-of-queens))
(queen-cols (- k 1))))
(enumerate-interval 1 board-size))
Explain why this interchange makes the program run slowly. Estimate
how long it will take Louis's program to solve the eight-queens
puzzle, assuming that the program in exercise solves
the puzzle in time T.